Introduction¶
So far, we have learned followings:
- Study Design
- Quantifying Extent of Disease
- Summarizing Data collected in the sample
- The Role of Probability
Probably, it is a good time to have a look a real world data, BRFSS data, set and how these knowledges are applied.
BRFSS Data¶
pacman::p_load(RCurl, foreign, downloader, survey, srvyr, ggplot2, dplyr, tidyverse)
brfss18 <- read.xport('data/LLCP2018.XPT')
sprintf("BRFSS data have %d recores, and %d number of variables", nrow(brfss18), ncol(brfss18))
brfss18[1:5,]
Research Question 1¶
Since the data is huge, let's narrow down our research question.
Prevalance of overweight/obesity and General health level (fair or poor) for each state in US
Codebook info for Selected Variables:
Education:
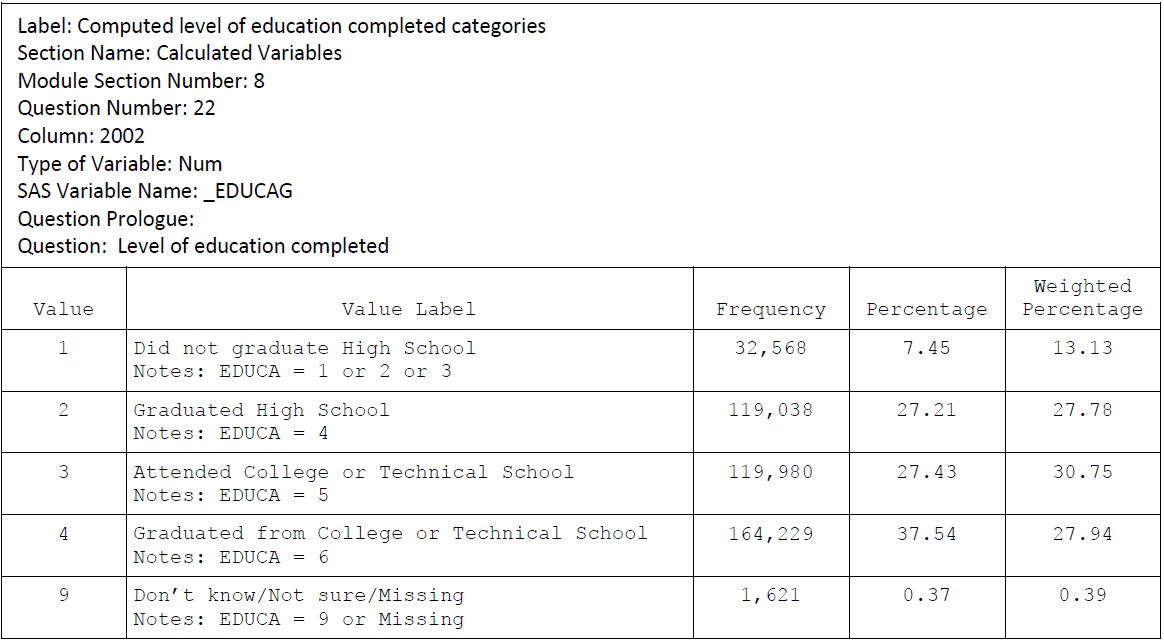
Income:
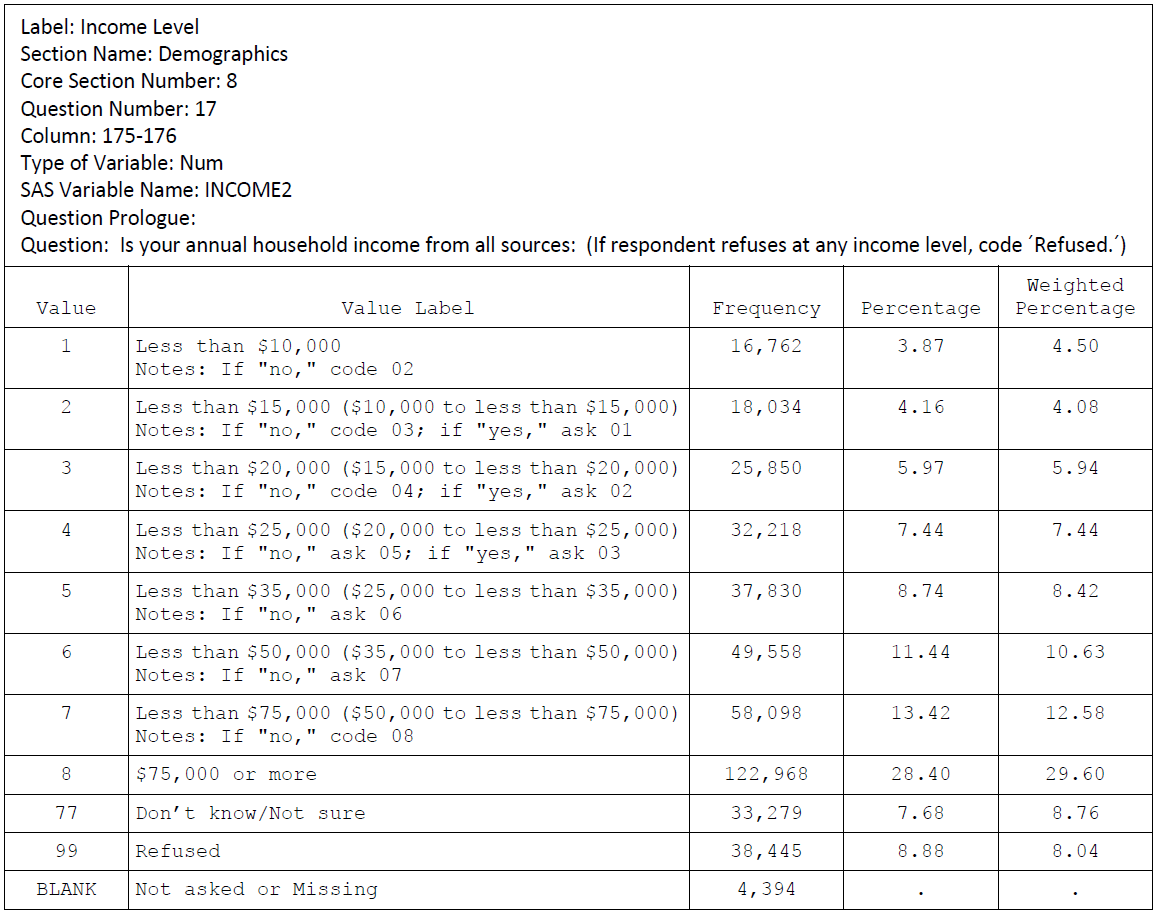
General Health:
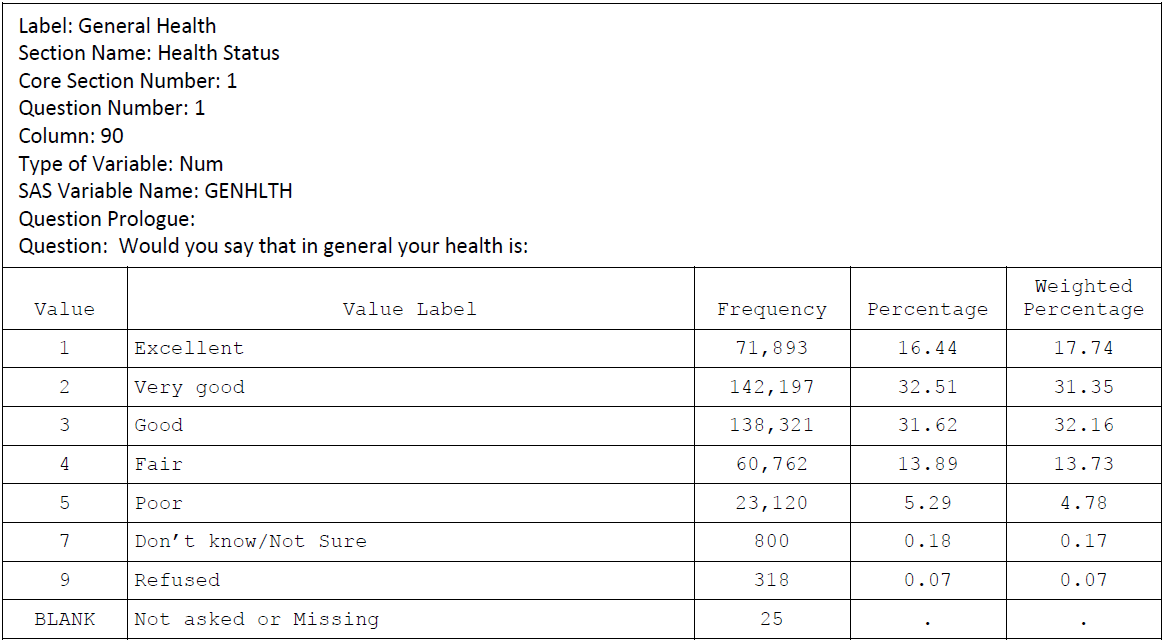
BMI:
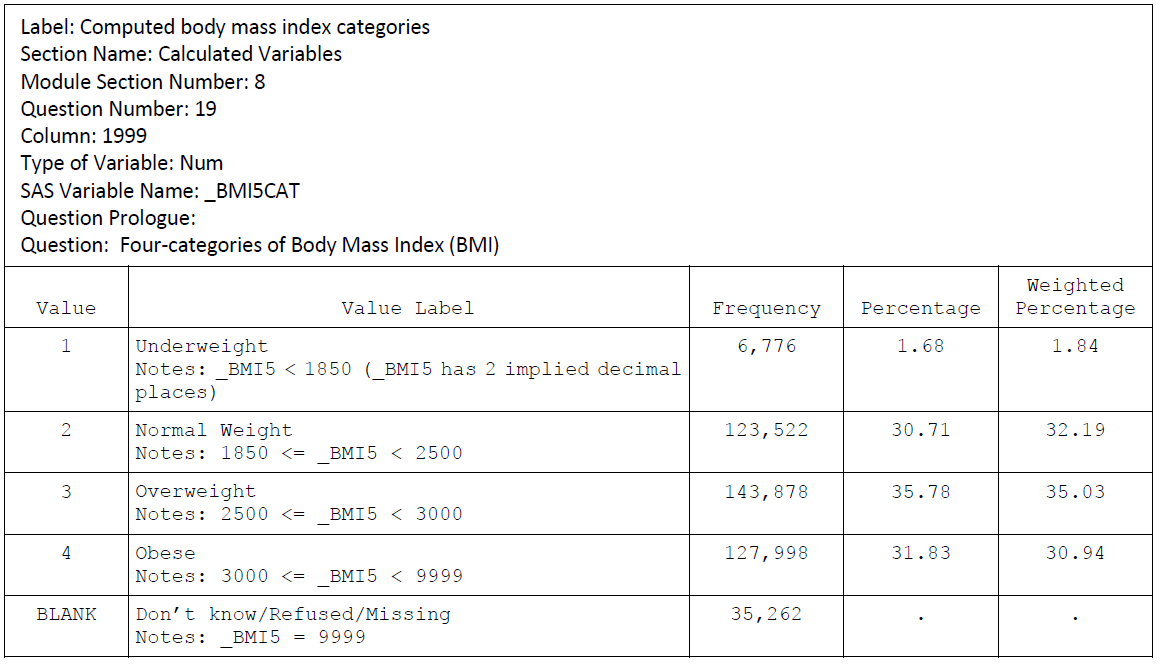
Sate ID info:
state.id <- read.csv("https://raw.githubusercontent.com/arilamstein/complexsurvey/master/brfss_state.csv", stringsAsFactors=F)
brfss18[1:5, c('X_PSU', 'X_STSTR','X_LLCPWT', 'X_STATE', 'X_EDUCAG', 'INCOME2', 'GENHLTH', 'X_BMI5CAT', 'SEX1')]
sub_brfss = brfss18 %>% select( c('X_STATE', 'X_EDUCAG', 'INCOME2', 'GENHLTH', 'X_BMI5CAT', 'SEX1') )
#sub_brfss = brfss18 %>% select( c('X_STATE', 'X_EDUCAG', 'INCOME2', 'GENHLTH', 'X_BMI5CAT', 'SEX') )
brfss.design <- brfss18 %>%
as_survey_design(ids=X_PSU,
weight=X_LLCPWT,
nest=T,
strata=X_STSTR,
variables= c(X_BMI5CAT, X_EDUCAG, INCOME2, GENHLTH, SEX1, X_STATE))
brfss.design <- brfss.design %>%
mutate(
X_EDUCAG2 = car::recode(X_EDUCAG, "1='<High School'; 2='Graduated High School'; 3='Attended College or Technical School'; 4='Graduated College or Technical School'; else=NA"),
X_EDUCAG2 = factor(X_EDUCAG2, levels = c('<High School', 'Graduated High School', 'Attended College or Technical School', 'Graduated College or Technical School')),
X_EDUCAG2 = fct_explicit_na(X_EDUCAG2),
X_BMI5CAT2 = car::recode(X_BMI5CAT, "c(3,4)=1; NA=NA; else=0"),
X_BMI5CAT2 = as.factor(X_BMI5CAT2),
X_BMI5CAT2a = car::recode(X_BMI5CAT2, "1='Obese/overweight'; NA=NA; else='Not Obese/overweight'"),
X_BMI5CAT2a = factor(X_BMI5CAT2a, levels=c('Obese/overweight', 'Not Obese/overweight'), ordered=TRUE),
X_BMI5CAT2 = fct_explicit_na(X_BMI5CAT2),
INCOME2a = car::recode(INCOME2, "1='<10,000'; 2='10,000~15,000'; 3='15,000~20,000'; 4='20,000~25,000'; 5='25,000~35,000'; 6='35,000~50,000'; 7='50,000~75,000'; 8='>75,000'; NA=NA; else=NA"),
INCOME2a = factor(INCOME2a, levels = c('<10,000', '10,000~15,000', '15,000~20,000', '20,000~25,000', '25,000~35,000', '35,000~50,000', '50,000~75,000', '>75,000')),
INCOME2a = fct_explicit_na(INCOME2a),
GENHLTH2 = car::recode(GENHLTH, "c(4,5)=1; c(1,2,3) = 0; NA=NA; else = NA"),
GENHLTH2 = as.factor(GENHLTH2),
GENHLTH2a = car::recode(GENHLTH2, "1='Fair/Poor'; NA=NA; else='G/VG/Excelent'"),
GENHLTH2a = factor(GENHLTH2a, levels=c('Fair/Poor', 'G/VG/Excelent'), ordered=TRUE),
GENHLTH2 = fct_explicit_na(GENHLTH2),
SEX1 = car::recode(SEX1, "1='MALE'; 2='FEMALE'; else=NA"),
SEX1 = factor(SEX1, levels = c('MALE', 'FEMALE') ) ,
SEX1 = fct_explicit_na(SEX1)
)
Take long time (3:52~4:07)
options(survey.lonely.psu = "certainty")
state.bmi <- brfss.design %>%
group_by(X_STATE, X_BMI5CAT2) %>%
summarize(prevalence = survey_mean(na.rm=T, vartype = c("ci")),
N = survey_total(na.rm=T)) %>%
mutate(X_STATE = as.character(X_STATE))
state.bmi[1:10,]
data(county.regions, package="choroplethrMaps")
county.regions[1:5,]
county.regions <- county.regions %>%
select(state.fips.character, state.name) %>% unique
county.regions[1:5,]
state.bmi <- state.bmi %>%
mutate(X_STATE = str_pad(X_STATE, 2, side="left", pad="0")) %>%
left_join(county.regions, by=c("X_STATE"="state.fips.character")) %>%
mutate(state.name = ifelse(X_STATE=="72", "puerto rico",
ifelse(X_STATE=="66", "guam", state.name)))
state.bmi[1:10,]
state.bmi %>% filter(X_BMI5CAT2==1) %>%
ggplot(aes(y=reorder(state.name, prevalence), x=prevalence, xmin=prevalence_low, xmax=prevalence_upp)) +
geom_point() +
geom_errorbarh(height=0) +
labs(y="State", x=NULL,
title="BMI Overweight and Obese by State",
caption="2014 CDC BRFSS") +
theme_bw() +
theme(axis.text.y=element_text(size=rel(0.8)))

state.bmi2 <- state.bmi %>%
filter(X_BMI5CAT2==1) %>%
select(region=state.name, value=prevalence)
choroplethr::state_choropleth(state.bmi2, title="Computed body mass index categories (overweight or obese) choropleth map", num_colors=9)

state.ht <- brfss.design %>%
group_by(X_STATE, GENHLTH2) %>%
summarize(prevalence = survey_mean(na.rm=T, vartype = c("ci")),
N = survey_total(na.rm=T)) %>%
mutate(X_STATE = as.character(X_STATE))
state.ht[1:5,]
state.ht <- state.ht %>%
mutate(X_STATE = str_pad(X_STATE, 2, side="left", pad="0")) %>%
left_join(county.regions, by=c("X_STATE"="state.fips.character")) %>%
mutate(state.name = ifelse(X_STATE=="72", "puerto rico",
ifelse(X_STATE=="66", "guam", state.name)))
state.ht[1:5,]
state.ht %>% filter(GENHLTH2==1) %>%
ggplot(aes(y=reorder(state.name, prevalence), x=prevalence, xmin=prevalence_low, xmax=prevalence_upp)) +
geom_point() +
geom_errorbarh(height=0) +
labs(y="State", x=NULL,
title="Health Condition Fair or Poor by State",
caption="2014 CDC BRFSS") +
theme_bw() +
theme(axis.text.y=element_text(size=rel(0.8)))

state.ht2 <- state.ht %>%
filter(GENHLTH2==1) %>%
select(region=state.name, value=prevalence)
choroplethr::state_choropleth(state.ht2, title="General Health level categories (fair or poor) choropleth map", num_colors=9)

Research Question 2¶
So far, we used survey design, and observational weights, X_LLCPWT, are used for the analysis. However, many times we may not need such weight modifications. This time, let's assume each sample in the survey have the same importance. and look at research question :
How is the prevalance of Overweight/Obesity and General Health level (fair or poor) with respect to Educational level or annual income in Wisconsin State?
Take Wisconsin state(55) from data
brfss18 <- brfss18 %>% tbl_df()
brfss_wisc <- brfss18 %>% filter(X_STATE == 55)
Do some preprocessing:
brfss_wisc <- brfss_wisc %>%
mutate(
X_EDUCAG2 = car::recode(X_EDUCAG, "1='<High School'; 2='Graduated High School'; 3='Attended College or Technical School'; 4='Graduated College or Technical School'; else=NA"),
X_EDUCAG2 = factor(X_EDUCAG2, levels = c('<High School', 'Graduated High School', 'Attended College or Technical School', 'Graduated College or Technical School')),
X_EDUCAG2 = fct_explicit_na(X_EDUCAG2),
X_BMI5CAT2 = car::recode(X_BMI5CAT, "c(3,4)=1; NA=NA; else=0"),
X_BMI5CAT2 = as.factor(X_BMI5CAT2),
X_BMI5CAT2a = car::recode(X_BMI5CAT2, "1='Obese/overweight'; NA=NA; else='Not Obese/overweight'"),
X_BMI5CAT2a = factor(X_BMI5CAT2a, levels=c('Obese/overweight', 'Not Obese/overweight'), ordered=TRUE),
X_BMI5CAT2 = fct_explicit_na(X_BMI5CAT2),
X_BMI5CAT2a = fct_explicit_na(X_BMI5CAT2a),
INCOME2a = car::recode(INCOME2, "1='<10,000'; 2='10,000~15,000'; 3='15,000~20,000'; 4='20,000~25,000'; 5='25,000~35,000'; 6='35,000~50,000'; 7='50,000~75,000'; 8='>75,000'; NA=NA; else=NA"),
INCOME2a = factor(INCOME2a, levels = c('<10,000', '10,000~15,000', '15,000~20,000', '20,000~25,000', '25,000~35,000', '35,000~50,000', '50,000~75,000', '>75,000')),
INCOME2a = fct_explicit_na(INCOME2a),
GENHLTH2 = car::recode(GENHLTH, "c(4,5)=1; c(1,2,3) = 0; NA=NA; else = NA"),
GENHLTH2 = as.factor(GENHLTH2),
GENHLTH2a = car::recode(GENHLTH2, "1='Fair/Poor'; NA=NA; else='G/VG/Excelent'"),
GENHLTH2a = factor(GENHLTH2a, levels=c('Fair/Poor', 'G/VG/Excelent'), ordered=TRUE),
GENHLTH2 = fct_explicit_na(GENHLTH2),
GENHLTH2a = fct_explicit_na(GENHLTH2a),
SEX1 = car::recode(SEX1, "1='MALE'; 2='FEMALE'; else=NA"),
SEX1 = factor(SEX1, levels = c('MALE', 'FEMALE') ) ,
SEX1 = fct_explicit_na(SEX1)
)
Prevalence of Overweight/Obesity, General Health with respect to educational level
tb_wisc <- brfss_wisc %>%
select(X_EDUCAG2, X_BMI5CAT2a, INCOME2a, GENHLTH2a, SEX1, X_BMI5CAT) %>%
group_by(X_EDUCAG2) %>%
summarize(prevalence_highBMI = sum(as.numeric(X_BMI5CAT2a) == 1) / sum(as.numeric(X_BMI5CAT2a) %in% 1:2),
prevalence_GENHLTH2a = sum(GENHLTH2a == 'Fair/Poor') / sum(!(GENHLTH2a %in% '(Missing)')),
prevalance_overweight = sum(X_BMI5CAT == 3, na.rm=T) / sum(X_BMI5CAT %in% 1:4, na.rm=T),
prevalance_obesity = sum(X_BMI5CAT == 4, na.rm=T) / sum(X_BMI5CAT %in% 1:4, na.rm=T),
N = n())
tb_wisc
Prevalence of General Health level(fair/poor) w.r.t Education level¶
tb_wisc %>%
ggplot( aes(y = prevalence_GENHLTH2a, x = X_EDUCAG2) ) +
geom_bar(stat="identity") +
geom_text(aes(label=round(prevalence_GENHLTH2a,2)), vjust=1.6, color="white", size=3.5)+
xlab('Education Level') +
ylab('Prevalence of Genral Health(fair/poor)') +
theme_bw() +
# theme_minimal() +
theme(
text = element_text(size = 17),
axis.text.x = element_text(angle=35, hjust = 1)
)

Relationship between Income and Educational level¶
brfss_wisc %>%
select(INCOME2a, X_EDUCAG2) %>%
group_by(INCOME2a, X_EDUCAG2) %>%
tally() %>%
group_by(INCOME2a) %>%
mutate(edu_ratio = n / sum(n)) %>% ggplot() +
geom_col(aes( x = INCOME2a, y = edu_ratio, fill = X_EDUCAG2),
position = "stack") +
xlab('Income') +
ylab('Education level proportions') +
theme_bw() +
# theme_minimal() +
theme(
text = element_text(size = 10),
axis.text.x = element_text(angle=35, hjust = .9)
)

Prevalence of General Health (Fair/Poor) w.r.t Annual Income¶
brfss_wisc %>%
select(X_EDUCAG2, X_BMI5CAT2a, INCOME2a, GENHLTH2a, SEX1, X_BMI5CAT) %>%
group_by(INCOME2a) %>%
summarize(prevalence_highBMI = sum(as.numeric(X_BMI5CAT2a) == 1) / sum(as.numeric(X_BMI5CAT2a) %in% 1:2),
prevalence_GENHLTH2a = sum(GENHLTH2a == 'Fair/Poor') / sum(!(GENHLTH2a %in% '(Missing)')),
prevalance_overweight = sum(X_BMI5CAT == 3, na.rm=T) / sum(X_BMI5CAT %in% 1:4, na.rm=T),
prevalance_obesity = sum(X_BMI5CAT == 4, na.rm=T) / sum(X_BMI5CAT %in% 1:4, na.rm=T),
N = n()) %>%
ggplot( aes(y = prevalence_GENHLTH2a, x = INCOME2a) ) +
geom_bar(stat="identity") +
geom_text(aes(label=round(prevalence_GENHLTH2a,2)), vjust=1.6, color="white", size=3.5)+
xlab('INCOME') +
ylab('Prevalence Gen. Health (Fair/Poor)') +
theme_bw() +
# theme_minimal() +
theme(
text = element_text(size = 15),
axis.text.x = element_text(angle=45, hjust = 1)
)

Distribution of Annual Income for residents in WI¶
brfss_wisc %>%
select(INCOME2a) %>%
group_by(INCOME2a) %>%
summarize(n = n()) %>%
ggplot( aes(y = n, x = INCOME2a) ) +
geom_bar(stat="identity") +
geom_text(aes(label=round(n/sum(n),2)), vjust=1.6, color = "white") +
geom_text(aes(label=n), vjust=-.3) +
xlab('INCOME') +
ylab('Frequency') +
theme_bw() +
# theme_minimal() +
theme(
text = element_text(size = 15),
axis.text.x = element_text(angle=45, hjust = 1)
)
